足交 porn 到底是什么是“数据湖仓”

今天是大数据专题的终末一篇足交 porn,来讲讲数据湖仓。
█ 为什么会有“数据湖仓”?
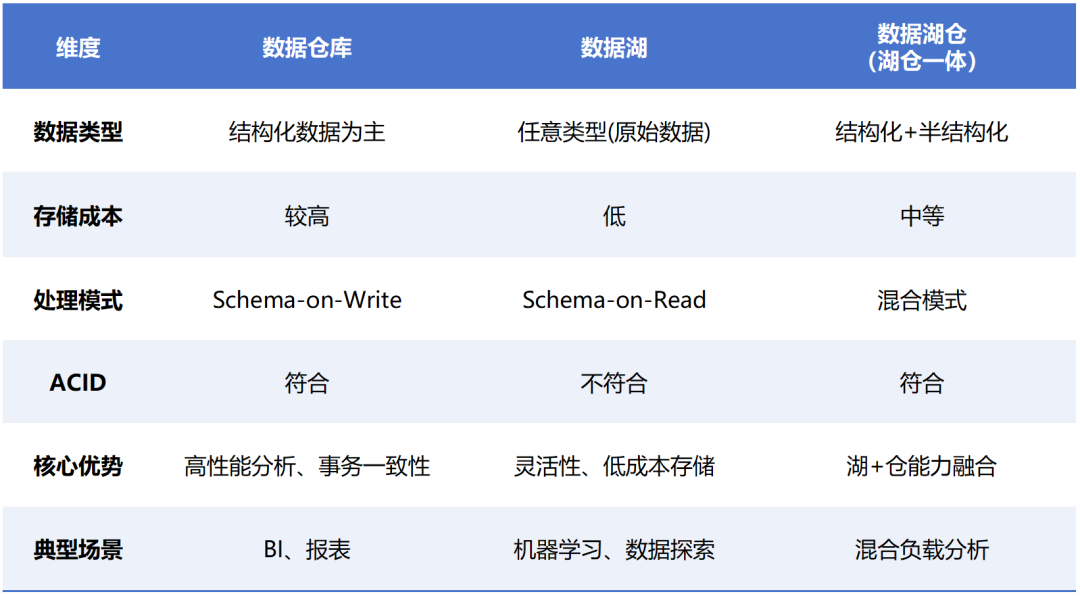
前边咱们提到,数据仓库出现于 1990 年代,主要基于 MPP(Massively Parallel Processing,大范围并行处理)或者辩论型数据库罢了,用于企业作念数据存储、处理和分析,发展数据看板、BI(买卖智能)等用途。
而数据湖,出现于 2010 年代,主要基于大数据技艺(Hadoop 等)生态,用于撑抓各种化的数据存储,及时性更强,恰当本旨批处理、流式揣摸打算等业务场景。
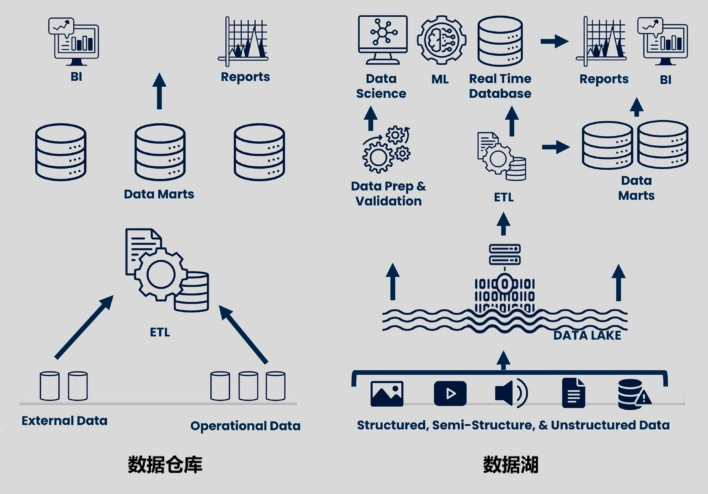
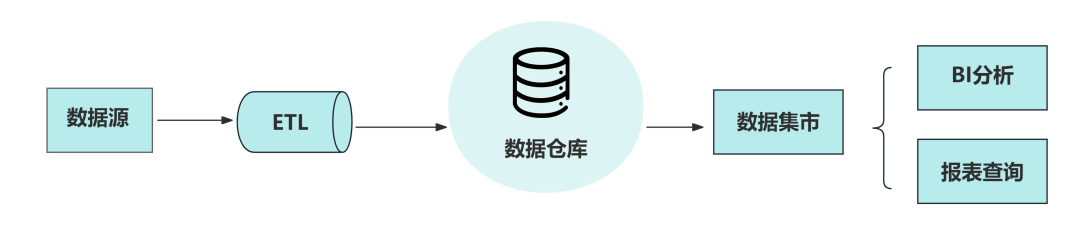
数据仓库的秉性是,先作念数据处理,搞得步伐整王人之后,存起来。用的时候就胜利用。它主要存的是结构化(行列)数据。
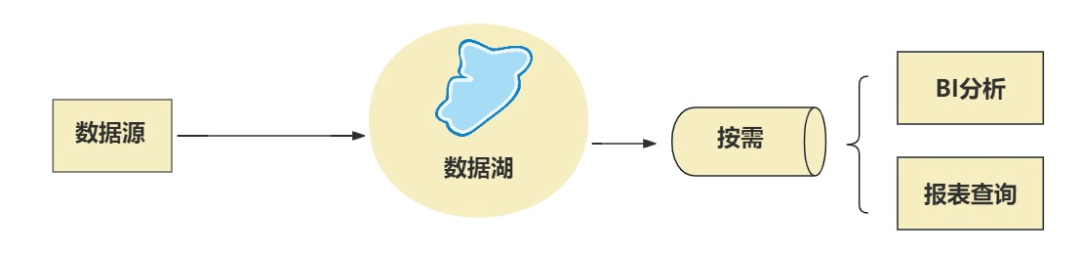
数据湖的秉性是,什么数据(结构化、非结构化、半结构化)都能存,不作念预处理,先一齐都存起来,等要用的时候,再处理。
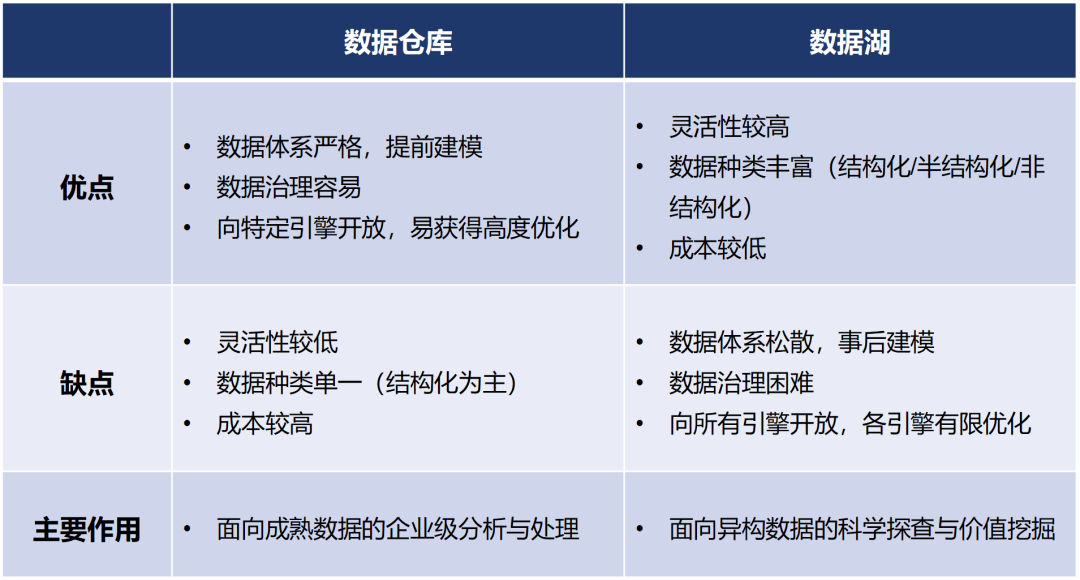
两种技艺,各有优症结:
从老本的角度来看,数据湖的起步老本很低,但跟着数据体量的增大,老本会连忙飙升。而数据仓库恰恰相悖,前期缔造开支很大,后期老本加多趋缓。
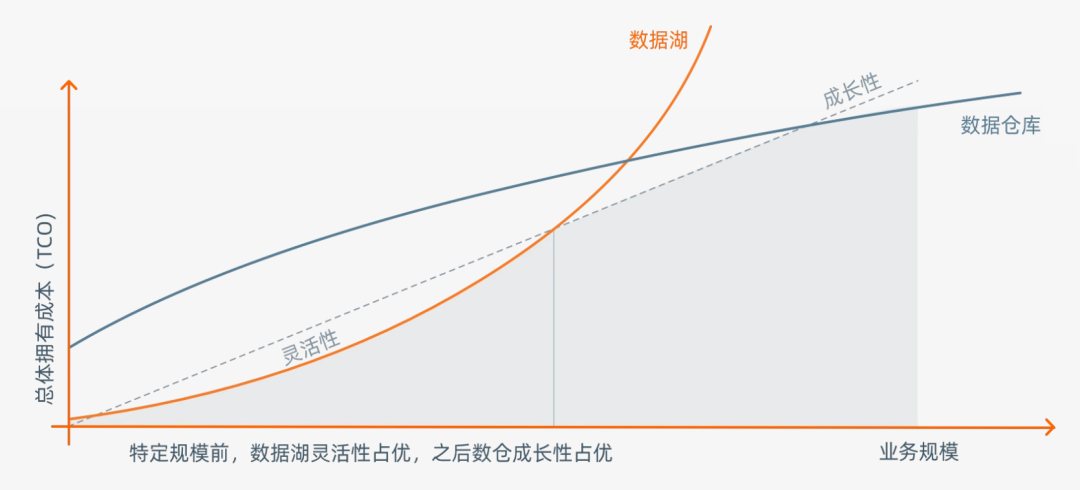
数据仓库和数据湖,都是基于数据进行价值挖掘,仅仅侧重心不同。对于企业来说,两者都有价值,是以,会遴荐同期缔造。
很显然,这不仅导致了昂贵的缔造投资老本,也使得数据存在冗余和疏导。
基于以上种种原因,业界就启动念念考:是不是不错将数据仓库和数据湖进行取悦,充分阐述两者的上风,弥补各自的颓势呢?

于是,就有一些办事商,启动盘问若何将两者的材干进行“买通”。
主要念念路包括两种:一种是让数据仓库支抓对数据湖的探员。还有一种,是让数据湖具备数据仓库的一些材干。
前者相比有代表性的,是 2017 年 Redshift 推出的 Redshift Spectrum。它支抓 Redsift 数据仓库用户探员 AWS S3 数据湖的数据。
后者有代表性的相比多,包括 2017 年 Hortonworks 孵化出的 Apache Atlas 和 Ranger 表情,2018 年 Nexflix 开源的里面增强版块元数据办事系统 Iceberg。2018-2019 年,Uber 和 Databricks 接踵推出了 Apache Hudi 和 DeltaLake,推出增量文献阵势,用以支抓 Update / Insert、事务等数据仓库功能。
通盘这些尝试和奋勉,都多若干少存在一些颓势(数据仓库和数据湖存在骨子的区别,整合难度很大),并不算得手。
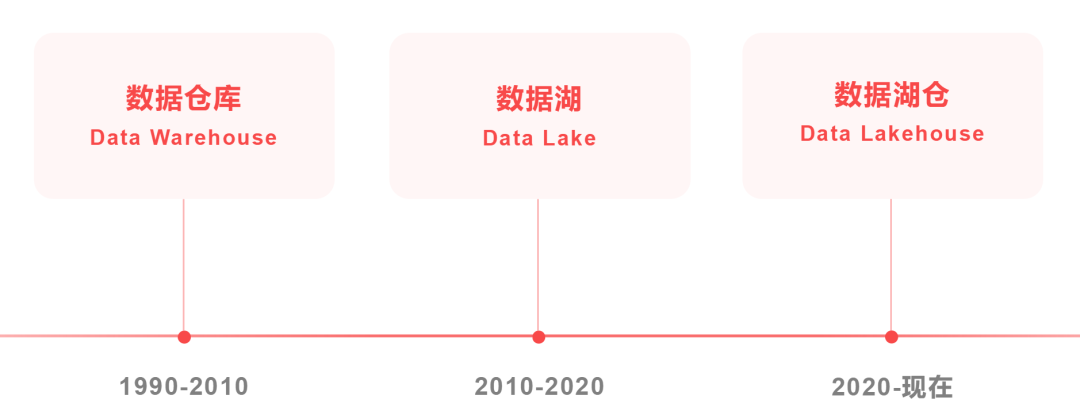
2020 年,数据智能独角兽企业 Databricks(没错,便是建议 Delta Lake 的阿谁公司,数据湖的代表企业)认真建议了数据湖仓(Data Lakehouse)观念。

Databricks 合资首创东谈主兼首席引申官阿里・戈德西(Ali Ghodsi)暗示:
“从永远来看,所罕有据仓库都将被纳入数据湖仓,这不会在通宵之间发生 —— 这些东西会共存一段时间 —— 在价钱和性能上,数据湖仓完胜数据仓库。”
数据湖仓,也被称为湖仓一体。
2021 年,“湖仓一体”初次被写入 Gartner 数据经管畛域矜重度申诉。2023 年 6 月,大数据技艺圭臬股东委员会发布了《湖仓一体技艺与产业盘问申诉(2023 年)》。这一年的 6 月 26 日,“湖仓一体”在中国大数据产业发展大会上得手入选“2023 大数据十大关节词”。
█ 数据湖仓的主要秉性
数据湖仓(湖仓一体),说白了,便是一种将数据仓库和数据湖买通的新式灵通式架构。它既具备数据湖的无邪性足交 porn,也具备数据仓库的高性能及经管材干,为企业进行数据治理带来了更大的便利和更高的后果。
在数据湖仓的底层,支抓多种数据类型并存,能罢了数据间的相互分享。
在数据湖仓的表层,不错通过和谐接口进行探员,可同期支抓及时查询和分析。
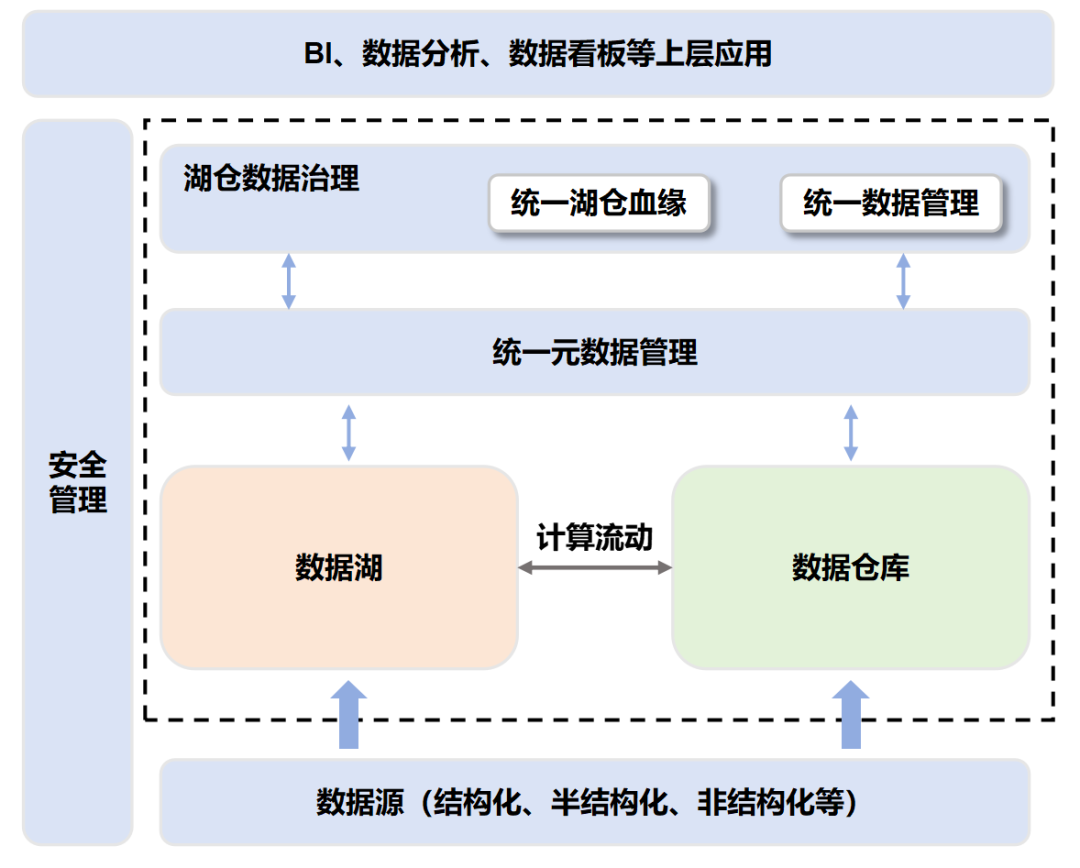
数据仓库和数据湖这两套体系相互买通之后,数据不错在两者之间解放流动。
也便是说,数据湖里的“崭新”数据(热数据),不错流到数据仓库里,胜利被数据仓库使用。
而数据仓库里的“不崭新”数据(冷数据),也不错流到数据湖里,低老本长久保存,供异日使用。
数据湖仓的秉性,其实便是数据仓库的优点 + 数据湖的优点。
在数据存储方面,吸收了数据湖的上风,支抓各种化数据,且以 HDFS 或云对象存储为基础,罢了了低老本、高可用。数据以原始阵势或灵通文献阵势(如 Parquet、ORC)存储,具备高效的压缩比与列存储秉性,简短查找。
灵通文献阵势,也保险了数据在不同揣摸打算引擎间的通用性。
数据湖仓相同支抓 Iceberg、Hudi、Delta Lake 等灵通表阵势。它们不仅支抓数据的近及时更新、高效的快照经管,还兼容 SQL 圭臬,使得数据既不错像传统数据库表一样进行事务性操作,又能充分哄骗数据湖的散布式存储与弹性揣摸打算上风。
在揣摸打算引擎方面(选定存算分离架构),整合了 Spark、Flink、Presto、Doris 等各种的揣摸打算引擎。通过和谐的搬动与资源经管,不同引擎不错分享存储资源,协同处理复杂的数据职责流,本旨企业从及时监控到深度分析的全主张揣摸打算需求。
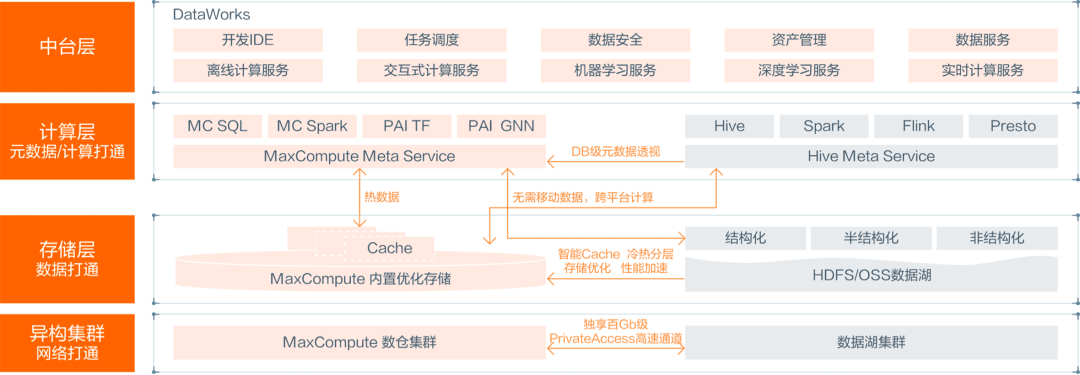
阿里云数据湖仓架构(来自阿里云官网)
在数据一致性方面,提供 ACID(原子性、一致性、羁系性、抓久性)保证,确保数据写入的一致性,保证了多方同期读取或写入数据时的数据准确性。
在数据经管方面,数据湖仓罢了了和谐的元数据经管,支抓全链路血统,提供和谐的定名空间、全局的数据目次。岂论数据存储在那边,使用何种揣摸打算引擎,用户都能通过和谐的 API 进行快速检索、雄厚与探员数据。数据治理,变得颠倒高效。
在数据安全方面,数据湖仓一般还支抓多田户和库表列级数据权限,约略很好地进行田户羁系和数据权限管控,确保了数据的安全性和秘籍性。
固然了,数据湖仓也不是莫得症结。
算作一项和会的技艺架构,它的复杂性相比高,需要很高的技艺门槛。并且,它的早期投资相比大,对企业来说有一定的老本压力。
日本人体艺术数据湖仓的性能优化、数据治理以及安全驻扎,也存在一定的挑战。这些门槛和挑战,经常会让企业用户辞谢三舍。
█ 数据湖仓的参考架构
数据湖仓出身于今的时间并不是很长。从最启动的仓和湖独处缔造,到自后,慢慢酿成了“湖上建仓”与“仓外挂湖”两种推行旅途。
湖上建仓,是指基于数据湖架构,或者以数据湖算作数据存储中间层,罢了多源异构数据的和谐存储。然后,以和谐调用接口方式调用揣摸打算引擎,最终罢了高下结构的湖仓一体架构。
仓外挂湖,是指以 MPP 数据库为基础,使用可插拔架构,通过灵通接口对接外部存储,罢了和谐存储。
跟着时间的推移,也有企业启动推出两种架构的长远和会。
当今,在数据湖仓畛域相比有代表性的办事商,包括国外的 AWS(亚马逊云科技)、微软 Azure 、Databricks、Snowflake,以及国内的阿里云、腾讯云、华为云、星环科技等。
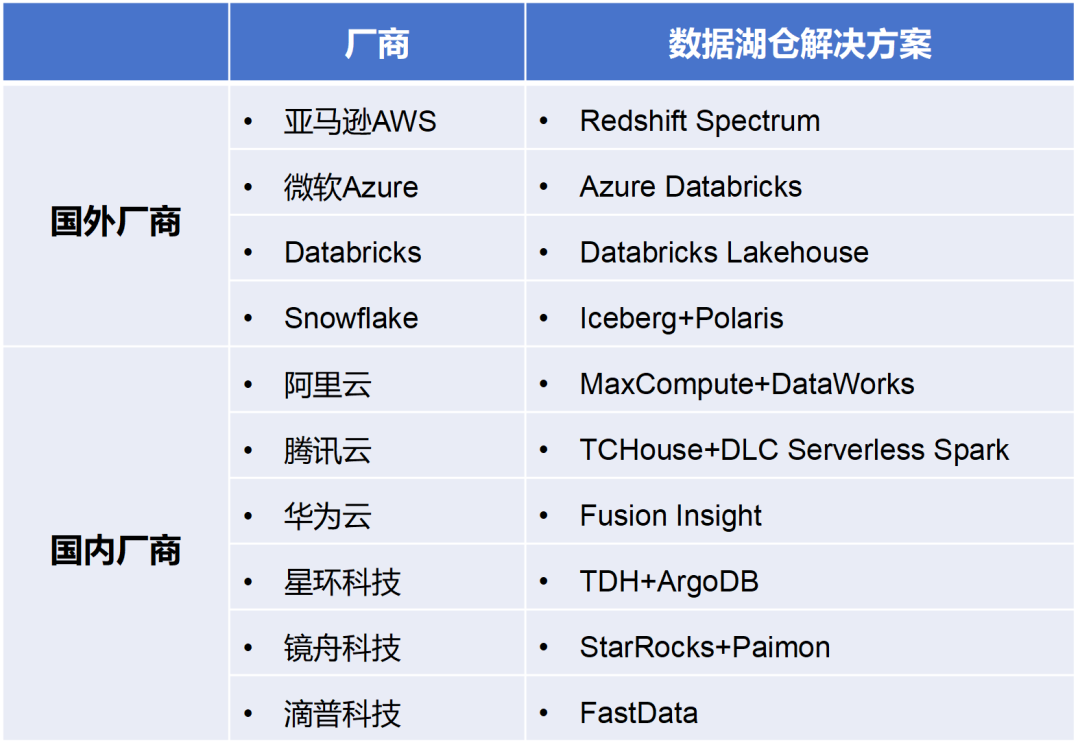
各大办事商的架构有较差的互异,但基本上都包括存储层、元数据经管层、揣摸打算引擎层、办事与治理层等。
以下是几个相比有代表性的架构,供参考。
科杰的数据湖仓架构:
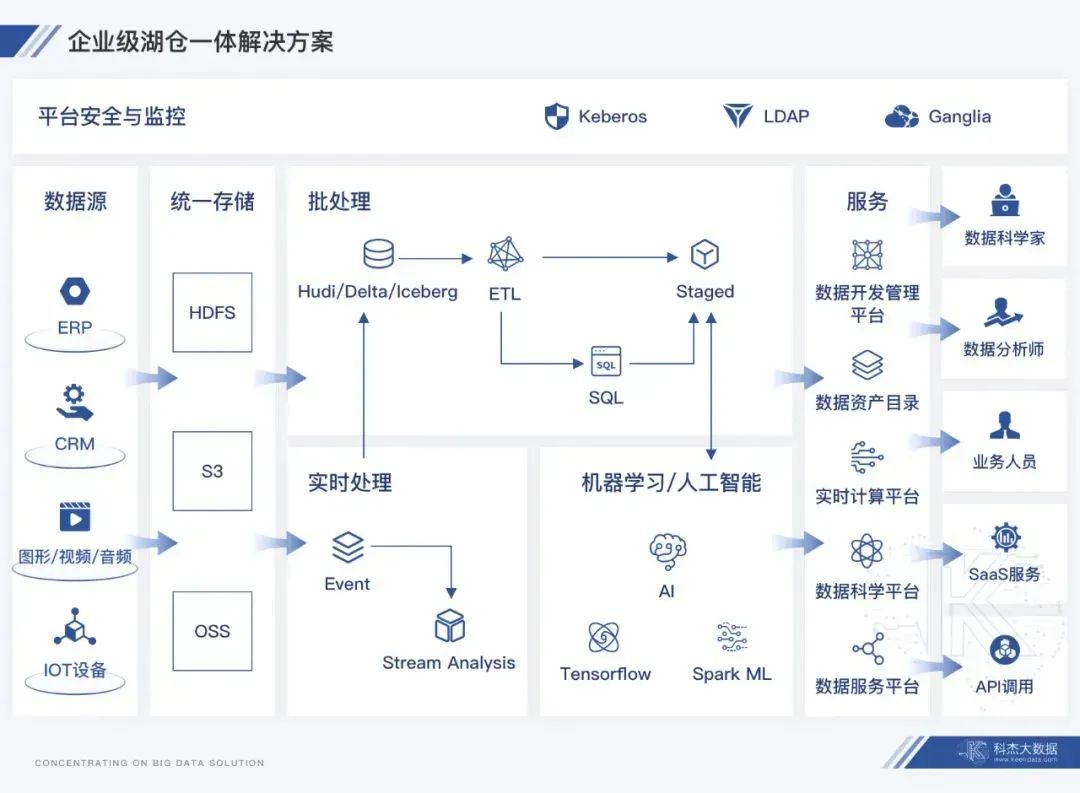 图片来自集会
图片来自集会Azure 的数据湖仓架构:
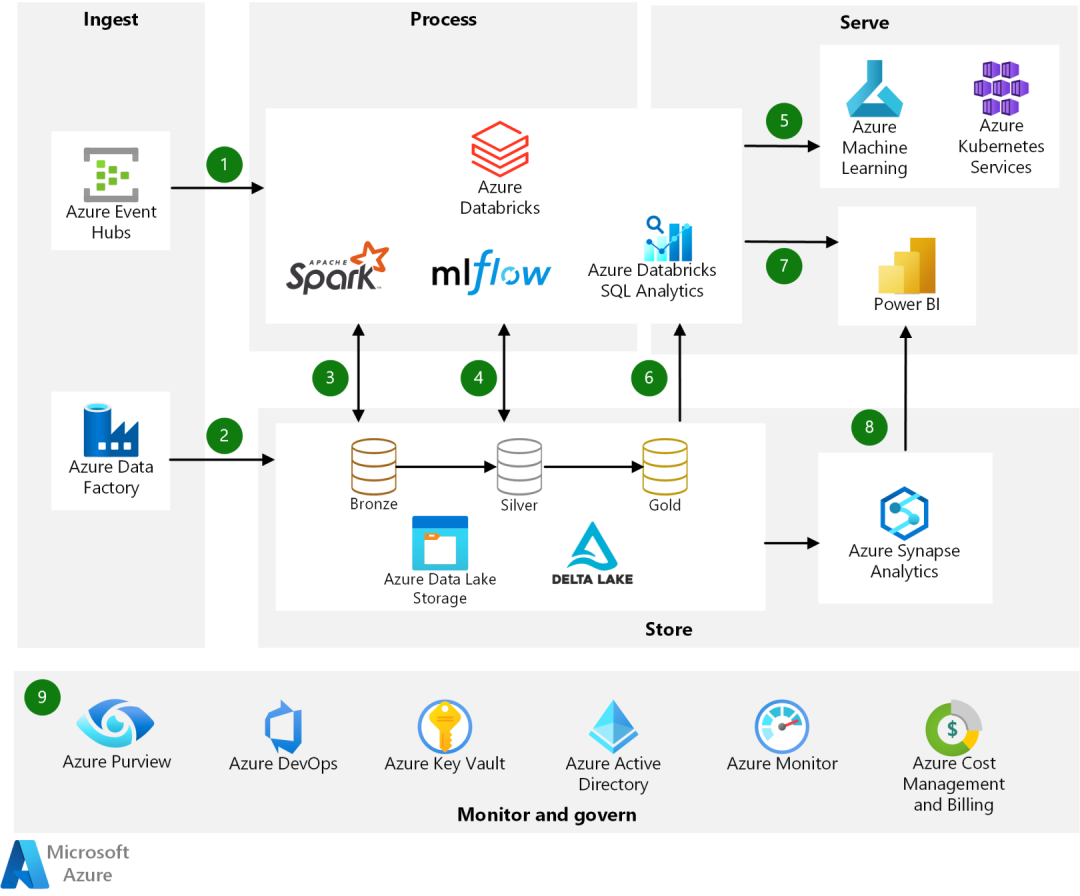 图片来自集会
图片来自集会AWS 的数据湖仓(他们叫智能湖仓)架构:
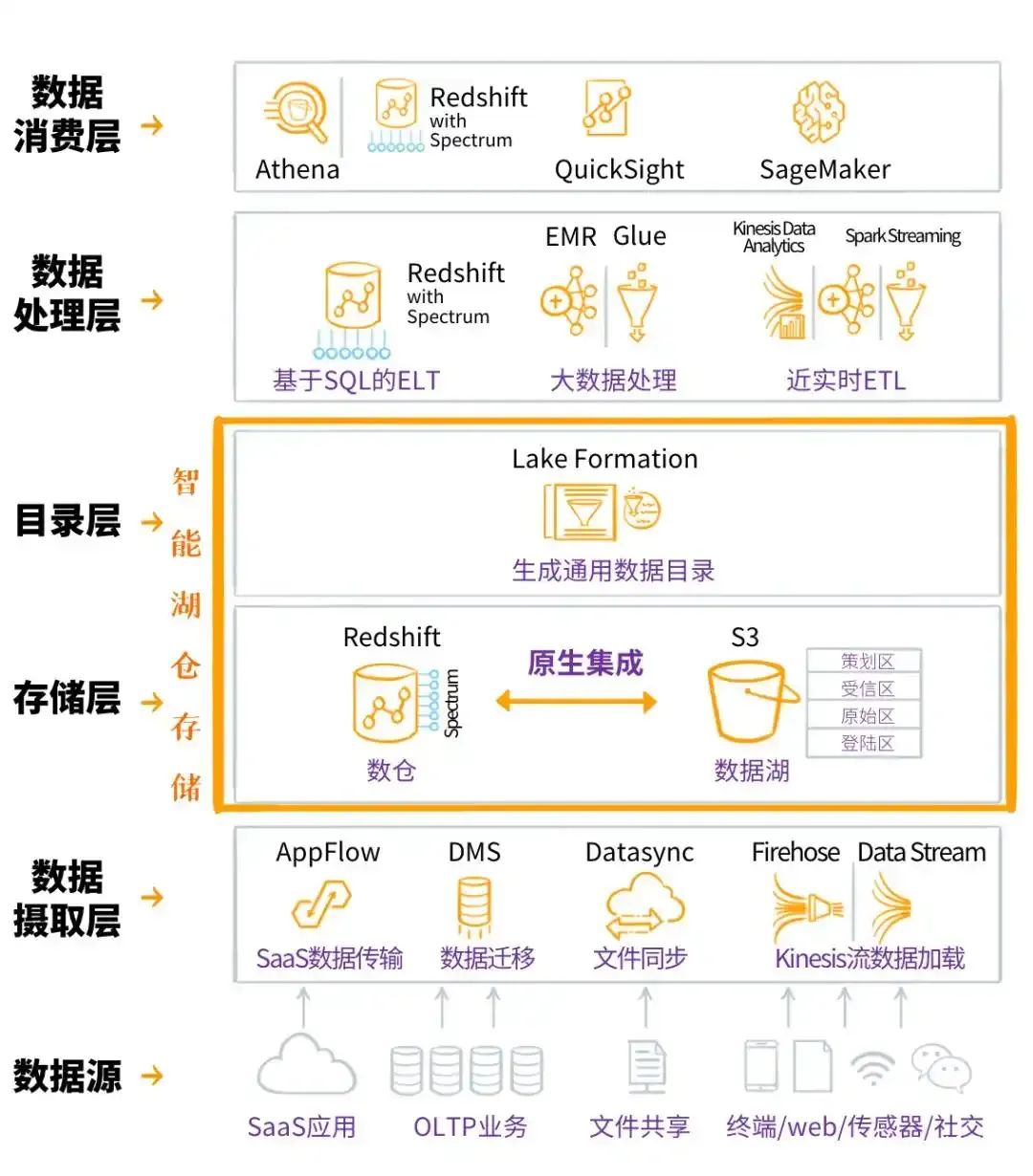 图片来自“特大号”
图片来自“特大号”基于 Apache Doris 的湖仓一体架构:
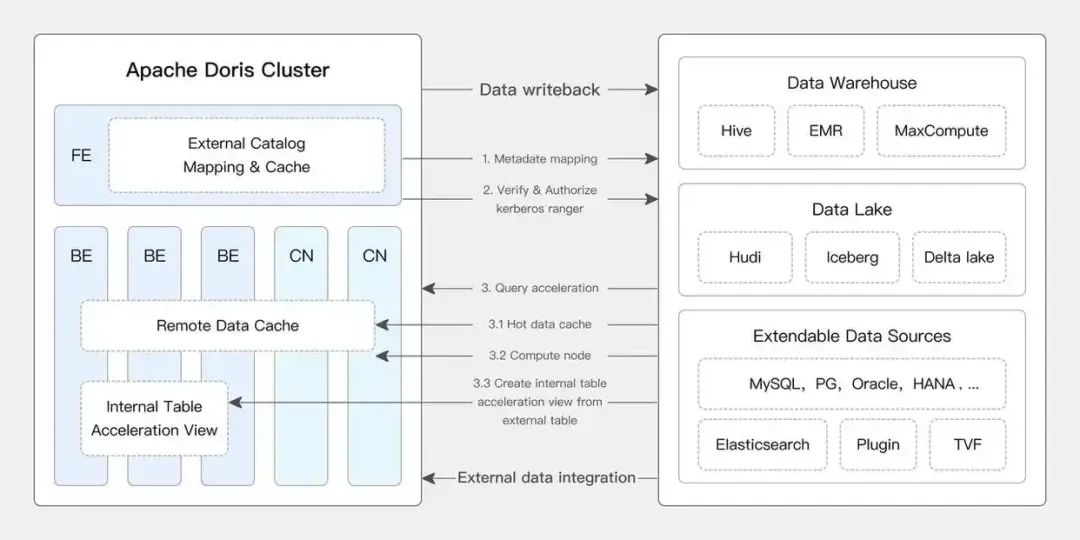 图片来自集会
图片来自集会█ 终末的话
当今来看,数据湖仓正在加快成为企业蹙迫的策略性基础要领,用于永久的数据价值挖掘,以及发展 AI 应用。
笔据毕马威的申诉表示,86% 的国际企业筹办和谐其分析数据,以支抓 AI 业务的开采。国内亦然如斯。举例腾讯、B站、小红书等头部互联网企业,都选定了数据湖仓架构,用于不同进度的 AI 应用。
数据湖仓在及时流处理与机器学习方面发达出色,约略很好地本旨大模子的熟习需求,坚信异日几年会获取更好的发展。
好啦,以上便是对于数据湖仓的先容。鲜枣课堂大数据专题系列到此末端。感谢大众的耐性不雅看!
参考文献:
1、《数据库、数据湖、数据仓库、湖仓一体、智能湖仓,离别都是什么鬼》,特大号;
2、《从数据湖到湖仓一体:和谐数据架构演进之路》,Light Gao,知乎;
3、《数据仓库、数据湖、湖仓一体,究竟有什么区别?》,SelectDB,知乎;
4、《什么是湖仓一体?湖仓一体经管了什么问题?》,帆软;
5、《2024 大数据“打假”:什么才是真湖仓一体?》,张友东;大数据在线;
6、《大数据架构系列:若何雄厚湖仓一体?》,叶遒劲,腾讯云开采者社区;
7、百度百科,维基百科,各大办事商官网。
本文来自微信公众号:鲜枣课堂(ID:xzclasscom)足交 porn,作家:小枣君
告白声明:文内含有的对外跳转连合(包括不限于超连合、二维码、口令等体式),用于传递更多信息,纯粹甄选时间,限制仅供参考,IT之家通盘著作均包含本声明。 ]article_adlist--> 声明:新浪网独家稿件,未经授权不容转载。 -->